French photonic quantum computing developer Quandela has experimentally validated a low-latency hardware integration path that connects its photonic Quantum Processing Units (QPUs) directly with NVIDIA accelerated high-performance computing (HPC) infrastructure. Presented at the ISC High Performance 2026 conference in Hamburg, Germany, the architecture moves beyond traditional cloud-hosted application programming interfaces (APIs) and asynchronous job queues. By leveraging the NVIDIA NVQLink interconnect, the milestone establishes a collocated, real-time hybrid computing pipeline where a quantum processor functions as a tightly coupled hardware accelerator alongside GPU clusters.
Eliminating Asynchronous Queue Latency via Direct Hardware Interconnects
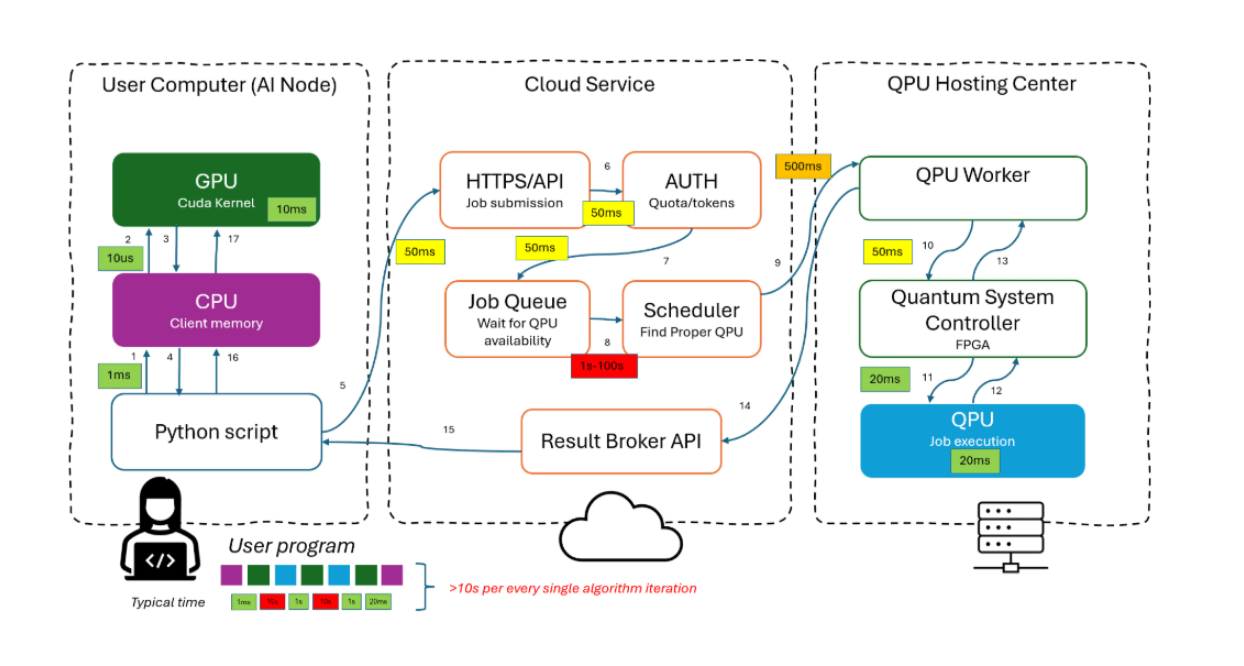
In conventional quantum cloud ecosystems, an artificial intelligence workload running on a GPU must hand data back to a classical host CPU to coordinate remote quantum job submissions. This asynchronous loop—comprising network serialization, cloud scheduling, queuing, and memory copies—introduces an end-to-end latency floor of approximately 5 seconds per data point, even if the quantum execution itself requires only a few milliseconds. This orchestration overhead acts as a severe structural bottleneck for Quantum Machine Learning (QML) applications, where a quantum layer must be evaluated repeatedly inside an active neural-network forward pass.
[ Traditional Cloud ] GPU ──► Host CPU ──► Cloud API ──► Scheduler Queue ──► QPU ( ≥ 5,000 ms Latency )
[ NVQLink Colocated ] GPU ═══════════ ( Low-Latency NVQLink ) ═══════════► QPU ( ~30 ms Latency )
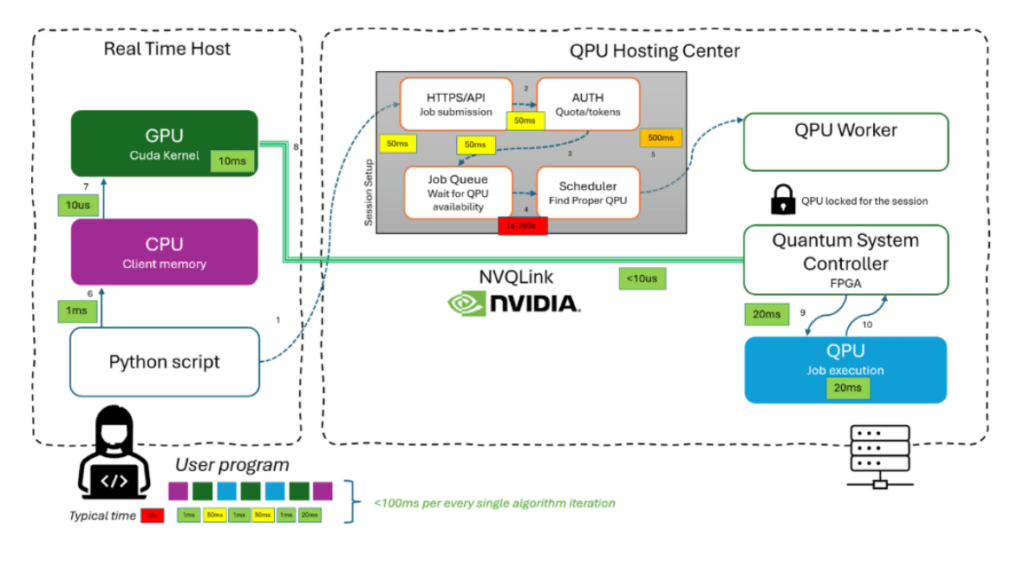
The validated hardware layout addresses this latency bottleneck by physically collocating the GPU host, an FPGA-based Quantum System Controller (QSC), and the Quandela photonic QPU within a shared sub-millisecond networking fabric. Regulated by a session-based reservation protocol, the host CPU locks the QPU and preconfigures its optical parameters before processing begins, granting the QSC exclusive runtime ownership. GPU kernels then communicate with the QSC directly via an NVQLink connection over a ConnectX-7 network interface. This dedicated pathway bypasses the host operating system, Python runtimes, and remote APIs, allowing the system to execute real-time inference loops directly inside the accelerated computing stack.
The Photonic Advantage: Persistent Configurations and Rapid Sampling
The real-time hybridization model is uniquely enabled by the distinct physical properties of photonic quantum architectures, which differ from matter-based qubit modalities:
- Persistent Circuit Configurations: In many photonic QML models, the underlying interferometric transformation matrix remains fixed throughout an active execution session. Moving between consecutive data points does not require re-executing a full control sequence; it requires only lightweight, localized phase updates to encode input parameters.
- High-Throughput Spatial Sampling: Once the optical network is configured, the processor extracts continuous data from a persistent physical transformation without replaying a state-preparation or reset routine between shots. Quandela’s current processors operate with an effective event rate approaching 100 kHz, allowing the system to acquire 1,000 useful samples in approximately 10 milliseconds.
Because an incremental phase update requires roughly 20 milliseconds and sample acquisition takes 10 milliseconds, the total hardware processing time per data point is brought down to approximately 30 milliseconds. By shrinking the surrounding network and software overhead to the sub-millisecond scale via NVQLink, the system ensures that classical orchestration no longer dominates the runtime profile. This structural efficiency yields maximum utilization of the accelerator, allowing thousands of real-time inference calls to be executed on a single, stable optical configuration.
Accelerating Photonic QML Frameworks and Energy-Efficient Inference
The low-latency execution model is explicitly designed to support hybrid software pipelines developed within Quandela’s MerLin framework, an open-source library engineered to embed photonic quantum models directly into standard PyTorch workflows. By enabling sub-millisecond tensor transfers directly into GPU-addressable memory, the architecture permits the execution of live Quantum Reservoir Computing, quantum feature maps, and hybrid convolutional-quantum neural network layers within a single forward pass. This framework was highlighted at the IEEE World Congress on Computational Intelligence (WCCI 2026), where the core MerLin research paper was nominated for the Regular Best Paper Award, highlighting growing cross-disciplinary validation from the broader classical AI research community.
Furthermore, the hardware integration optimizes system-level energy efficiency. Recent benchmarks tracking the energetic advantages of photonic computing show that direct physical execution of high-dimensional optical transformations consumes less power per inference operation than digital simulation of the same matrices on traditional supercomputers. By combining this low thermal profile with the elimination of power-intensive CPU-to-GPU memory serialization cycles, the collocated architecture outlines a sustainable deployment model for sovereign AI initiatives, enterprise data centers, and industrial high-performance computing facilities seeking scalable quantum-classical hardware acceleration.
The comprehensive technical press release, system latency benchmarks, and architectural schematics can be reviewed via the Quandela Media Center here, while the underlying software compilation mechanics and runtime workflows are detailed in the Quandela Technical Research Blog here.
June 23, 2026
