
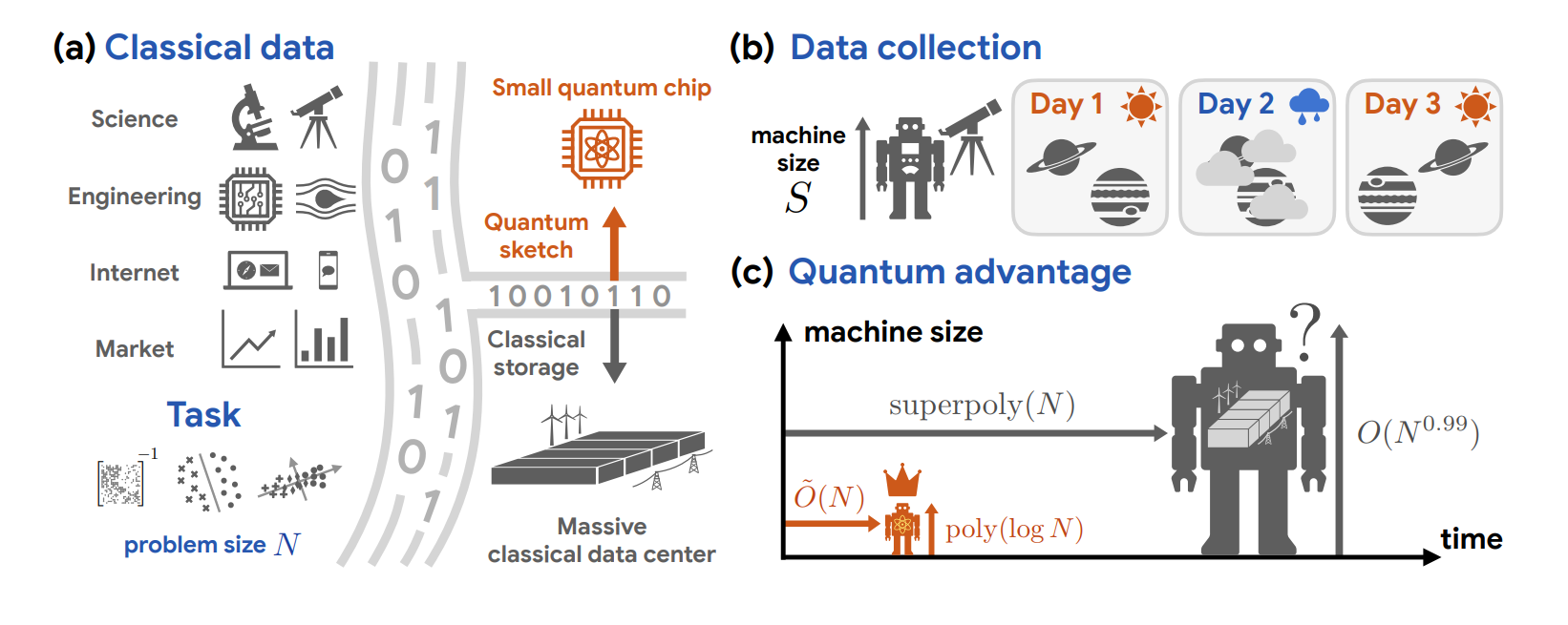
Researchers from Caltech, Google Quantum AI, MIT, and Oratomic have published a technical paper demonstrating an exponential space advantage for quantum computers in processing classical data. The research, titled “Exponential quantum advantage in processing massive classical data,” addresses the “data loading problem”—the historical difficulty of accessing classical data in quantum superposition without the prohibitive memory overhead of Quantum Random Access Memory (QRAM).
The study introduces a framework called quantum oracle sketching, which enables a quantum computer to construct coherent queries from streaming classical data samples. Rather than storing a dataset in its entirety, the algorithm processes each sample “on the fly” by applying incremental quantum rotations. These rotations accumulate to approximate a quantum oracle, allowing the system to execute quantum linear algebra algorithms while discarding samples immediately after use. The researchers prove that this method achieves a quadratic relationship between sample complexity and quantum queries, which is established as the fundamental limit governed by the Born rule.
The primary result is a rigorous proof that a quantum processor of polylogarithmic size (e.g., approximately 60 logical qubits) can perform large-scale classification and dimensionality reduction on datasets that would require an exponentially larger classical machine to achieve equivalent performance. This exponential space advantage is information-theoretic and independent of computational complexity conjectures; it persists even if classical machines are granted unlimited computation time. The researchers demonstrate that for specific tasks, a 300-logical-qubit processor provides a memory capacity that exceeds the physical storage limits of any conceivable classical system.
The team validated these advantages using real-world datasets, including IMDb movie review sentiment analysis and single-cell RNA sequencing. The results showed a four to six order-of-magnitude reduction in memory consumption compared to classical streaming and sparse-matrix algorithms. These numerical experiments utilized fewer than 60 logical qubits, suggesting that the hardware required to implement such advantages is significantly closer to current experimental capabilities than the hardware required for Shor’s algorithm or other cryptanalytic tasks.
To facilitate classical readout, the researchers developed an interferometric classical shadow protocol. This allows for the construction of compact classical models from massive data streams that can then be used for downstream machine learning tasks, such as high-dimensional linear classification. The core framework has been open-sourced in JAX, supporting integration with modern machine learning pipelines and GPU/TPU acceleration. This work positions classical data processing as a natural domain for quantum utility, providing a verifiable test of quantum mechanics at the complexity frontier.
For the complete technical proofs and methodology, consult the official research paper on arXiv here. Further context on the mathematical foundations of the data loading solution can be found on the Quantum Frontiers blog here. Detailed analysis of the “decryption threshold” and its relation to cryptographic foundations is available via the Quantum Computing Report (QCR) Qnalysis here.
April 13, 2026

Leave A Comment