
IBM Quantum has expanded its fault-tolerant roadmap by reporting a unified structural synthesis that bridges high-rate quantum low-density parity-check (qLDPC) codes with algebraic outer block constraints. Announced via an architectural briefing by Director of IBM Research Jay Gambetta, the corporate workflow integrates two key milestones: the in-situ generation of magic state factories natively within the Bicycle Architecture, and a collaborative theoretical framework with the Massachusetts Institute of Technology (MIT) on concatenating large-alphabet Quantum Reed-Solomon codes over high-rate inner blocks.
By treating highly correlated errors inside a single physical block as single-digit variations within a larger Galois field, the joint compiler architecture enables standard 144-qubit “gross” bivariate bicycle codes to operate reliably at a uniform physical noise floor of 10-3. This configuration allows the system to transition directly into the teraquop regime—requiring logical error rates below one-quadrillionth per qubit-round—while reducing total physical space overhead relative to unconcatenated 288-qubit alternative frameworks.
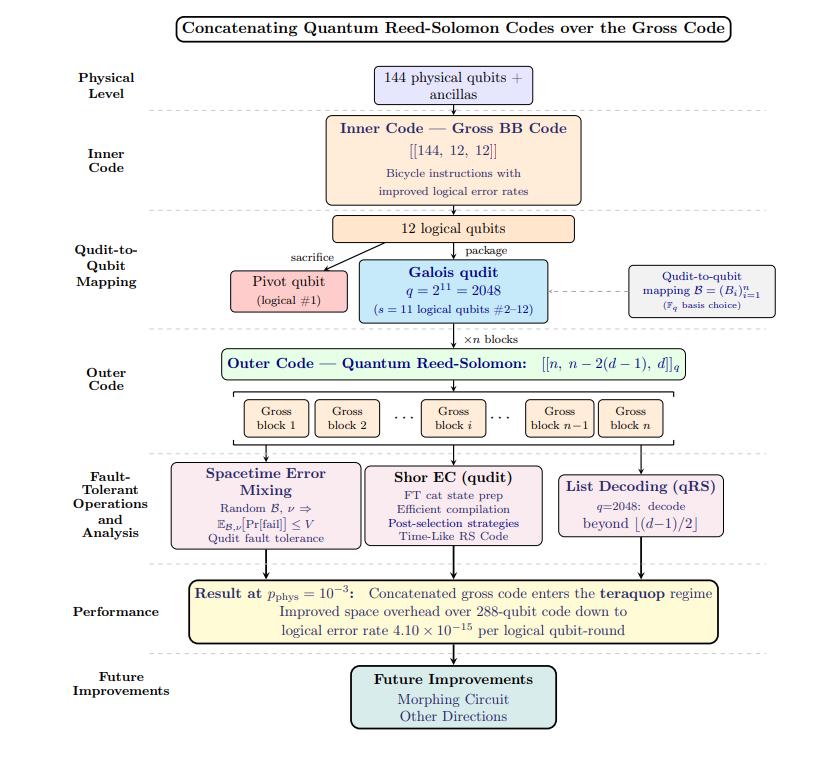
Technical Architecture: Galois Qudit Mapping and Algebraic Outer Subsystems
The primary engineering obstacle encountered when concatenating a high-rate outer code over a multi-qubit inner block is that individual logical qubits inside a common hardware block do not fail independently. A localized, bursty noise event or decoding failure on a single substrate chip induces highly correlated error distributions across all embedded registers. Traditional qubit-based outer codes with localized check distances quickly collapse under these burst patterns, as a single inner-block failure propagates into an uncorrectable multi-qubit outer logical fault.
To insulate data from these spatial correlations, the IBM and MIT engineering teams introduced a specialized qudit-to-qubit mapping topology. The architecture isolates the 12 logical qubits native to a single gross bivariate bicycle block and separates their operational roles:
- The Pivot Allocation: A single logical qubit is sacrificed to act as an unencoded processing node, executing the internal code stabilization routines, state injections, and cross-block logic instructions required to drive the surrounding memory layout.
- The Data Packaging: The remaining 11 logical data qubits are bound together to function mathematically as a single, large-alphabet Galois qudit possessing a finite field dimension of 2048.
By converting the block’s internal registers into a unified algebraic element, any internal error vector—regardless of its weight or distribution across those 11 qubits—is evaluated by the outer code as a single block-weight error of weight one. The outer code tier is built using non-binary Quantum Reed-Solomon codes with optimal parameters defined by the quantum Singleton bound. Operating in a regime where the block length is significantly smaller than the alphabet dimension, the architecture exploits the unique properties of high-dimensional list decoders. Because random physical faults are statistically unlikely to align with the specific high-weight logical symmetries of a large-alphabet field, a classical Guruswami-Sudan list-decoding variant can efficiently isolate and correct typical space-like errors well beyond the standard half-minimum-distance boundary.
Fault-Tolerant Syndrome Extraction & Spacetime Error Mixing
Extracting the syndromes of the outer Reed-Solomon code requires executing cross-block checks across adjacent gross code modules. The architecture implements a lightweight, non-local variant of the Shor error correction scheme custom-engineered for Galois qudits. To circumvent the extensive time latency associated with traditional trapped-ion transport or dedicated superconducting coupler configurations, the system generates high-dimensional qudit cat states completely offline using localized, measurement-based sequences. These states are compiled using optimized bicycle instruction sets, where a single, continuous series of physical rotations makes multiple future stabilizer measurements native to the underlying hardware layer.
To eliminate the extensive physical footprint required by continuous, repetitive measurement validation, the platform implements an overcomplete basis configuration where syndrome extractions are dynamically bound by an additional, “time-like” Reed-Solomon code layer. This time-like protection mechanism operates via a specialized matrix optimization protocol. To counter the reality that real-world logical errors do not occur with uniform mathematical probability across an inner chip’s substrate, IBM introduced spacetime error mixing. By applying a randomized selection protocol to the underlying qudit-to-qubit mapping vectors and the time-like syndrome multiplier coefficients, the compiler structurally scrambles the true physical error distribution before processing. This guarantees that the aggregate logical error rate can be bounded using manageable, numerically estimated statistics. Simultaneously, this large-alphabet configuration introduces an exotic fault-tolerance property unique to qudit structures: a single physical data fault occurring mid-circuit is exponentially suppressed by the high field dimension. Consequently, an unusually lightweight extraction sequence remains highly resilient when scaled across 2048-dimensional fields.
Native In-Situ Magic State Factories
This structural modularity directly complements IBM’s concurrent milestone detailing internal state preparation logic. A persistent bottleneck in scaling universal, fault-tolerant architectures has been the engineering overhead of magic state factories—isolated, highly specialized hardware sub-systems dedicated to distilling the non-Clifford states required to unlock non-classical algorithmic acceleration. Standard architectural roadmaps typically demand dedicated physical chips, complex interconnect lines, and universal adapter modules to pipe these states from external factories into the main logic processing blocks.
New research conducted in collaboration with the Ding Research Group at Yale University demonstrates that the gross code modules are sufficient to build and sustain high-fidelity magic state factories in-situ, completely eliminating the need for architectural reconfiguration or separate, specialized hardware components. This native distillation model operates via a two-stage circuit-level sequence:
- Direct In-Situ Injection: Low-fidelity, noisy raw magic states are directly loaded into the active gross code fabric using specialized injection protocols. This technique maps the physical injection circuits to the native layout of the bivariate bicycle code without interrupting neighboring stabilization loops.
- Bicycle-Optimized Distillation: Once injected, the low-fidelity states undergo localized, high-throughput distillation sub-routines. These protocols exploit non-obvious circuit-level optimizations developed by Yale researchers Kun Liu and Shifan Xu, allowing the internal Logic Processing Units of the gross code blocks to filter, concentrate, and upgrade the raw states into high-fidelity operational resources within the primary code block.
By unifying code concatenation with in-situ magic state generation, the updated roadmap provides a continuous, highly modular framework. This configuration allows industrial operators to scale system performance linearly, swap or recalibrate individual superconducting chip modules without stalling active calculations, and tune target logical error rates dynamically without changing the underlying physical hardware layout.
The complete technical manuscript detailing the algebraic outer code concatenation mechanics can be reviewed directly via the open-access arXiv repository here, with the specialized companion research on native in-situ injection protocols accessible via the arXiv injection data log here and the localized distillation framework available via the arXiv distillation design profile here. For the strategic industrial timeline, architectural layout diagrams, and supplementary commentary regarding magic state factory compilation within the gross code framework, read Jay Gambetta’s primary update published on LinkedIn here.
June 6, 2026

Leave A Comment